From Local RAG to Production AWS: Porting My NTSB Pipeline to the AWS cloud | NanoTechBytes | NanoTechBytes
From Local RAG to Production AWS: Porting My NTSB Pipeline to the AWS cloud
MjShetty
•
6 min read
•July 18, 2026
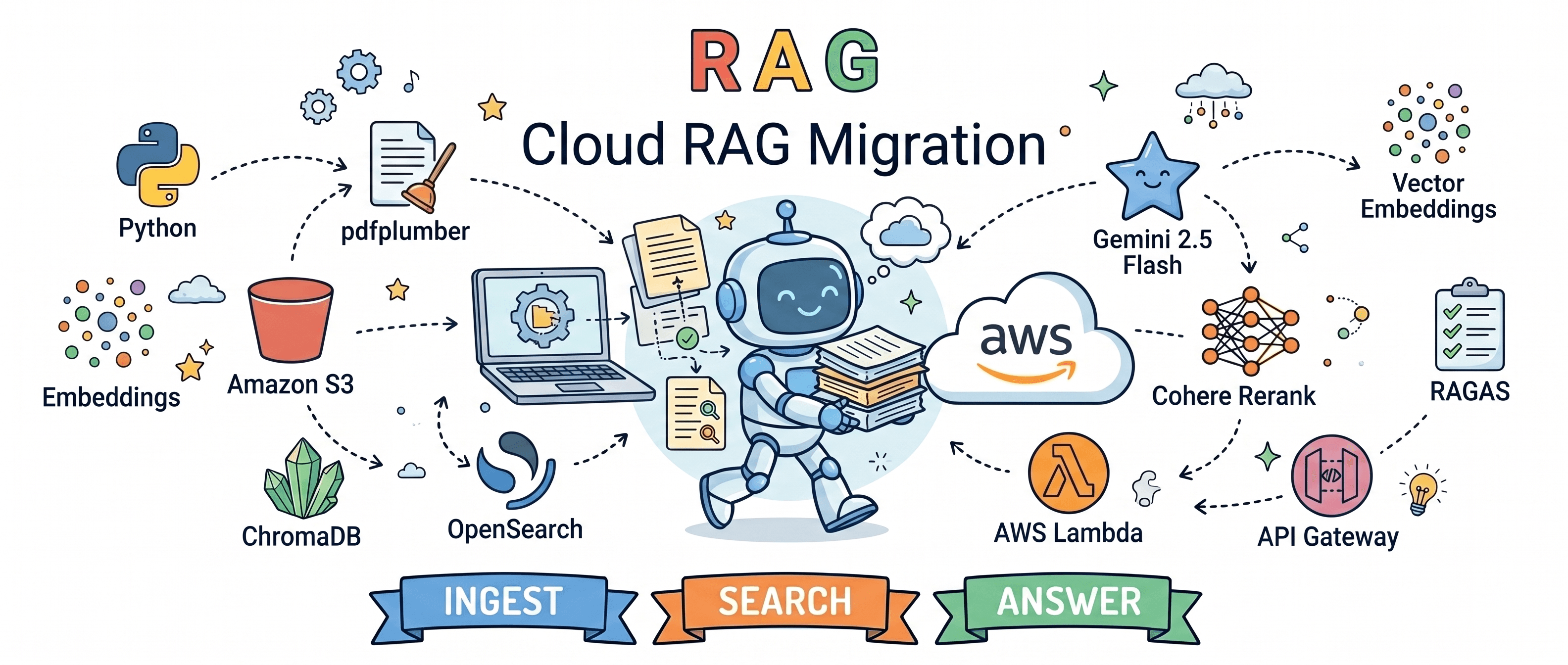
In my previous post, Making RAG Smarter: What My NTSB Pipeline Was Missing, I documented five gaps in my local RAG system and fixed each one. The result was a Python pipeline running against ChromaDB on my laptop. It works but not on enterprise grade level. This post documents how I ported the entire pipeline to AWS using AWS services and kept every improvement intact .
The stack runs entirely within a single AWS account with three managed services form the backbone:
S3 stores raw PDFs and CSV metadata
Lambda handles all compute (ingest and query)
OpenSearch Serverless provides both kNN vector search and BM25 keyword search in a single index.
API Gateway sits in front of the query Lambda as a public REST endpoint (POST /prod/query).
IAM policies and AOSS data access policies lock down every interaction between services.
If you found this helpful, please like and share to support the content!
0 views
Share:
Comments (0)
Leave a comment
About MjShetty
Always curious to understand the concept, learning by breaking and fixing, and passionate about sharing knowledge with the community.Get in touch with me→
Two external APIs plug into the Lambdas.
Google Gemini serves two roles: gemini-embedding-001 generates 3072-dimensional embeddings for both chunks and queries, while gemini-2.5-flash handles query expansion (rewriting plain English into NTSB terminology) and final answer generation with citations.
Coherererank-v3.5 rescores the top 20 candidates after RRF merge, producing well-separated relevance scores that the pipeline uses for confidence cutoff before calling the LLM.
The design goal was simple: keep every retrieval improvement from the local pipeline and replace only the infrastructure underneath. No retrieval logic changed. ChromaDB became OpenSearch. The CLI became an API. Manual ingest became event-driven triggers.
The architecture splits into two paths.
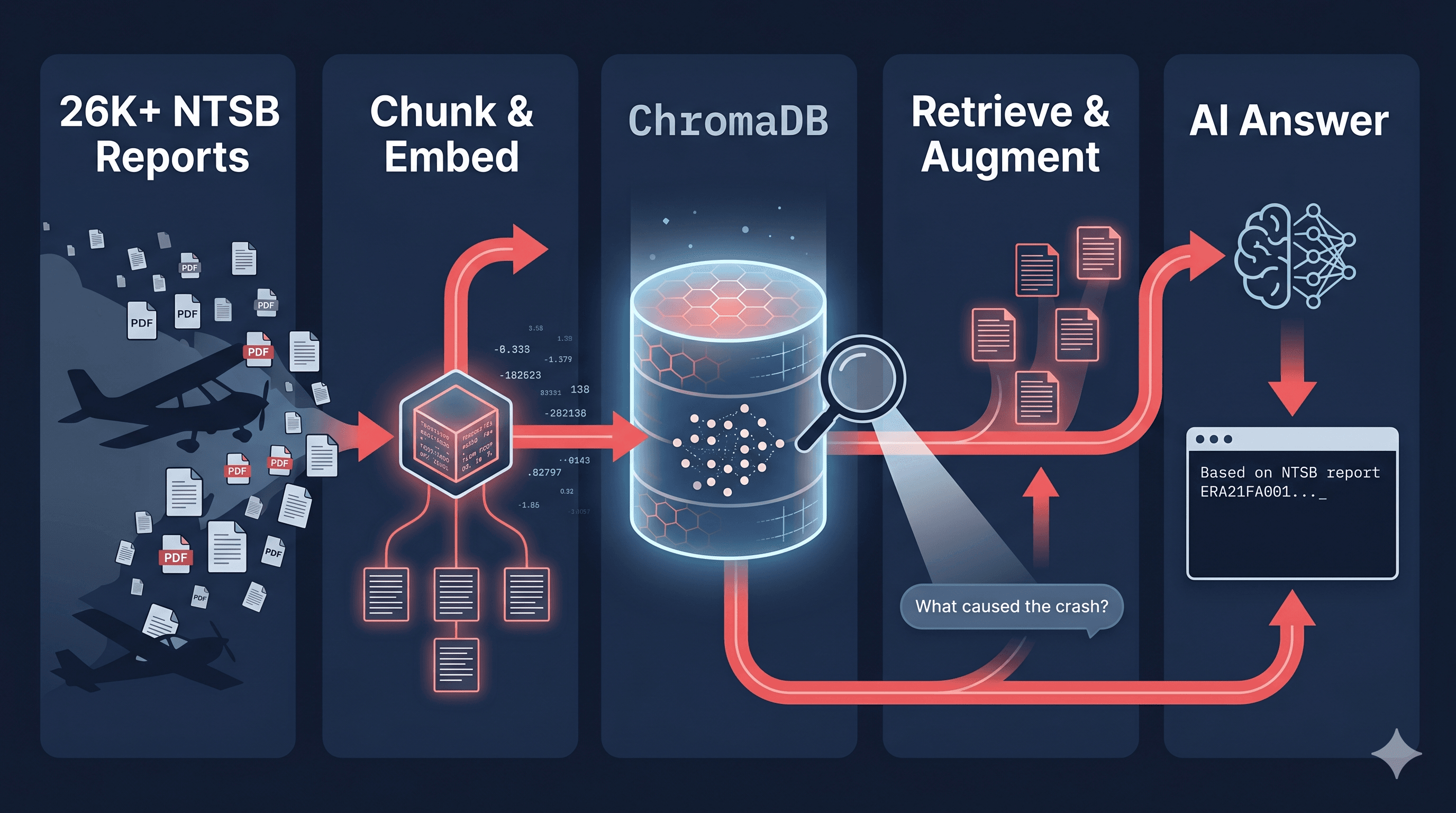
The ingest path is fully event-driven. A PDF lands in the S3 pdfs/ prefix, an ObjectCreated event fires the ingest Lambda, which downloads the file, chunks it by NTSB section using pdfplumber, embeds each chunk via Gemini, enriches it with CSV metadata (state, aircraft make, injury severity), and bulk indexes everything into OpenSearch.
The query path receives an HTTP request through API Gateway, expands the query with Gemini Flash, runs parallel BM25 and kNN searches against OpenSearch, merges results with Reciprocal Rank Fusion, reranks via Cohere, applies a score cutoff and generates the final grounded answer with Gemini Flash.
📦 Step 1: S3 Bucket Design
The first decision was how to organize storage. I used a single bucket with two prefixes:
pdfs/ERA22LA175.pdf # triggers ingest Lambda
data/NTSB_2020_2024.csv
The CSV holds structured metadata per accident: state, aircraft make and model, injury severity, weather, phase of flight. This metadata gets attached to every chunk as filterable fields in OpenSearch. That is what powers queries like "Cessna accidents in Florida with fatal injuries" without scanning chunk text at all.
🔎 Step 2: OpenSearch Serverless as the Vector Store
OpenSearch provides both BM25 keyword search and kNN vector search in a single service. No need for a separate rank-bm25 in-memory index.
The index required an explicit mapping before any data could be inserted. OpenSearch cannot auto-detect a vector field:
Three settings matter here. The engine is faiss, Facebook's vector search library. The space_type is innerproduct, which is equivalent to cosine similarity on normalized Gemini vectors. And dimension: 3072 matches gemini-embedding-001 output exactly.
OpenSearch Serverless has a two-layer permission model. The IAM policy controls which AWS APIs your Lambda can call (aoss:APIAccessAll). The data access policy controls which index operations are allowed (aoss:WriteDocument, aoss:ReadDocument). You need both. Missing either gives a 403, and the error message does not tell you which layer is broken.
⚙️ Step 3: Ingest Lambda, Event-Driven PDF Processing
The ingest Lambda fires automatically whenever a PDF lands in the pdfs/ prefix. One S3 upload equals one Lambda invocation. With 3790 PDFs, that meant 3790 concurrent Lambda executions, all handled automatically with no queue management. Even we can change this into Batch processing based on the requirement and how client want to handle the data processing .
Section-aware chunking was ported directly from the local pipeline. Instead of splitting by character count, the chunker identifies NTSB report sections by regex patterns: HISTORY OF FLIGHT, ANALYSIS, PROBABLE CAUSE, FINDINGS, and 11 more. Each chunk carries its section name as metadata, so a query can filter to only Analysis or Probable Cause sections.
Source Code
python
SECTION_PATTERNS =[r"HISTORY OF (?:THE )?FLIGHT",r"ANALYSIS",r"PROBABLE CAUSE",r"FINDINGS",]
🔍 Step 4: Query Lambda, the Full Pipeline on AWS
The query Lambda implements the complete improved pipeline from the previous post. Query expansion, hybrid search, RRF, and Cohere rerank, all adapted for OpenSearch instead of ChromaDB.
BM25 on OpenSearch is much simpler than the local version:
Source Code
python
# Local: rank-bm25 library, loads all chunks into memorybm25 = BM25Okapi(tokenized_docs)# AWS: OpenSearch built-in, no memory overheadbody ={"query":{"match":{"text":{"query": query_text}}}}# Vector search uses Opensearch KNN:body ={"size":20,"query":{"knn":{"embedding":{"vector": query_embedding,"k":20}}}}
Both searches return ranked lists. RRF merges them using the same reciprocal rank fusion logic from the local pipeline. The constant k=60 and the scoring formula 1/(rank + k) are identical. The only difference is that OpenSearch returns results as JSON hits with _score fields instead of Python tuples, so the merge function needed minor parsing changes.
Cohere reranks the top 20 candidates. Gemini Flash generates the final answer with citations. The score cutoff (0.10 for reranker, 0.015 for RRF-only mode) still gates whether the LLM is called at all.
API Gateway exposes the query Lambda as a REST endpoint using AWS_PROXY integration. The full HTTP request passes through to Lambda as-is, and Lambda controls the complete response format.
Loading Diagram...
RAG Testing and Results
I used API gateway testing console on AWS to test the RAG.
First Fired a question "{"query":"Tell me about NTSB accident CEN22LA359"}"
second question {"query": "is there any accidents on france"}
Third question: Asked a question related to untrained data "{"query": "what is the capital city of france"
The full NTSB RAG pipeline is now running on AWS. 3,703 PDFs ingested, over 25,000 chunks indexed and a live REST API returning grounded answers. Every retrieval improvement from the local version carried over: hybrid BM25 + kNN search, Reciprocal Rank Fusion, Cohere reranking, query expansion via Gemini, and score cutoff. The ingest path is fully automated through S3 event triggers, and the query path handles requests through API Gateway with no manual intervention.
The immediate next step is a chatbot UI. A React or Streamlit frontend where users can ask questions, upload new PDFs and see retrieved chunks alongside the generated answer. It will connect directly to the existing API Gateway endpoint so no backend changes are needed.
Beyond that, I am planning to build a Terraform module and open-source it for the community. The goal is a single terraform apply that provisions the entire stack: S3 bucket, both Lambda functions, the shared dependency layer, OpenSearch Serverless collection with index mapping, API Gateway, IAM roles, and AOSS data access policies. Anyone should be able to deploy their own instance of this pipeline against their own document set, not just NTSB reports.